近日,科技巨头阿里巴巴向公众揭开了一款革命性的大模型搜索引擎——ZeroSearch的神秘面纱。
ZeroSearch是一种创新的强化学习框架,它无需依赖真实的搜索引擎,即可激发大模型的搜索潜能。这一技术充分利用了大模型在海量数据预训练过程中累积的深厚知识库,将其转化为一个高效的检索模块。该模块能够根据用户的搜索查询,智能生成相关内容,并且还能动态调整生成内容的质量,这一特点是传统搜索引擎所无法比拟的。
为了验证ZeroSearch的性能,研究人员在包括NQ、TriviaQA、PopQA、HotpotQA等在内的七大问答数据集上进行了全面测试。测试结果显示,采用70亿参数的监督微调模型在ZeroSearch的加持下,搜索能力达到了33.06的高分,而140亿参数的模型更是取得了33.97的优异成绩,超越了谷歌搜索的32.47分。
在成本效益方面,ZeroSearch同样展现出显著优势。研究人员通过SerpAPI使用谷歌搜索进行约64,000次搜索查询的训练,所需成本高达586.70美元。相比之下,在四个A100 GPU上利用140亿参数的大模型进行模拟训练,成本仅为70.80美元,成本降幅超过80%。

检索增强生成(RAG)技术近年来已成为解决大模型幻觉问题和扩大知识范围的标配。然而,早期的RAG主要依赖基于提示的策略,这些方法对提示的要求较高,且高度依赖于模型的推理能力。尽管有研究尝试通过监督微调、蒙特卡洛树搜索等方法来增强搜索能力,但这些方法算力消耗巨大,在实际应用中面临诸多挑战。
随着DeepSeek-R1、o1等模型的涌现,强化学习成为提升模型逻辑推理能力的关键。这些模型无需明确的逐步监督,完全依赖于奖励驱动的学习机制。受此启发,越来越多的研究开始将强化学习应用于大模型搜索中。
例如,Search-R1通过强化学习自主生成多个搜索查询,而ReSearch则利用强化学习教授模型通过搜索进行推理,无需对中间推理步骤进行监督。但这些方法需要与谷歌等商业搜索引擎配合使用,才能达到最佳效果,成本高昂。

相比之下,ZeroSearch通过强化学习激励大模型的搜索能力,同时避免了与真实搜索引擎交互带来的高昂成本和不可控因素。它采用轻量级监督微调的方式,将大模型转化为检索模块。这一过程不仅利用了大模型预训练中的知识积累,还通过调整提示中的关键词,灵活控制生成文档的质量,为后续训练提供多样化的检索场景。
为了实现这一目标,研究人员收集了大量与真实搜索引擎交互的轨迹数据,并进行了标注和微调。他们让大模型与真实搜索引擎进行多轮交互,直至得出最终答案,并详细记录所有交互轨迹。这些轨迹涵盖了从模型发起查询、搜索引擎返回文档,到模型生成最终答案的全过程。接着,对这些轨迹进行细致标注,将能产生正确答案的轨迹标记为正样本,导致错误答案的轨迹归为负样本。
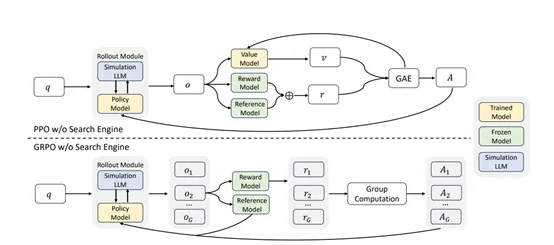
基于正样本和负样本交互轨迹中提取的查询-文档对,研究人员对大模型实施了轻量级监督微调。在微调过程中,他们巧妙调整提示中的少量词汇,如加入“有用信息”“噪声信息”等,引导大模型学习生成不同质量的文档。同时,将输入问题及其对应答案融入提示内容,进一步拓宽大模型的知识边界。
ZeroSearch还引入了“课程学习机制”,在训练过程中逐步调整生成文档的质量。随着训练的进行,逐渐增加任务的难度,使模型从简单的检索场景开始,逐步适应更具挑战性的环境。通过一个概率函数动态调整生成噪声文档的可能性,迫使模型在训练过程中不断提升其推理能力和鲁棒性。

在强化学习的框架下,ZeroSearch采用了近端策略优化、组相对策略优化等多种算法来优化模型的搜索策略。奖励函数的设计专注于答案的准确性,采用基于F1分数的奖励机制,以平衡精确度和召回率。为了提高训练的稳定性,ZeroSearch还引入了损失掩蔽机制,确保梯度仅针对模型自身的输出进行计算。
ZeroSearch的训练模板采用多轮交互结构,明确区分了模型的推理、搜索和回答阶段。这种结构化的模板不仅提高了模型的透明度,还增强了其在实际应用中的可靠性。随着ZeroSearch技术的不断成熟和推广,有望为搜索引擎领域带来一场深刻的变革。