近期,关于OpenAI的o3人工智能模型在基准测试上的表现引发了广泛讨论和质疑。这一争议的核心在于,OpenAI首次发布o3模型时宣布的高分成绩与第三方基准测试结果之间存在较大差异。
去年12月,OpenAI自豪地宣布,其o3模型在极具挑战性的数学问题集FrontierMath上取得了突破性的成绩,正确回答了超过四分之一的问题。这一成绩远超竞争对手,排名第二的模型仅能正确回答约2%的问题。OpenAI首席研究官Mark Chen在直播中强调,o3模型在内部测试中,通过激进的计算设置,达到了超过25%的正确率,远超市场上所有其他产品。
然而,事情似乎并没有那么简单。上周五,负责FrontierMath的Epoch研究所公布了其对o3模型的独立基准测试结果,发现o3的得分仅为约10%,远低于OpenAI此前声称的最高分数。这一结果立即引发了外界对OpenAI透明度和模型测试实践的质疑。
值得注意的是,OpenAI在12月份公布的基准测试结果中,其实已经包含了一个与Epoch测试结果相符的较低分数。Epoch在报告中指出,测试设置的差异以及评估使用的FrontierMath版本更新可能是导致结果差异的原因。Epoch还提到,OpenAI在内部评估时可能使用了更强大的计算框架和更多的测试时计算资源。
与此同时,ARC Prize基金会也在X平台上发布消息,证实了Epoch的报告。ARC Prize指出,公开发布的o3模型是一个针对聊天/产品使用进行了调整的不同模型,且所有发布的o3计算层级都比他们测试的版本要小。这一信息进一步加剧了外界对OpenAI基准测试结果的疑虑。
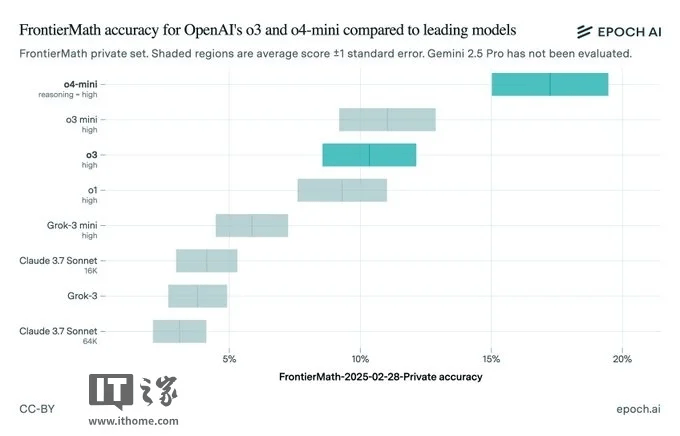
尽管公开版本的o3未能完全达到OpenAI测试时的表现,但OpenAI并未因此停滞不前。该公司后续推出的o3-mini-high和o4-mini模型在FrontierMath上的表现已经优于o3,且计划在未来几周内推出更强大的o3版本——o3-pro。
然而,这一系列事件再次提醒人们,在看待人工智能基准测试结果时需要保持谨慎。尤其是当结果来自一家有产品需要销售的公司时,更需要审慎对待。随着人工智能行业竞争的加剧,各供应商纷纷急于通过推出新模型来吸引眼球和市场份额,这也导致基准测试“争议”变得越来越常见。
事实上,这并非OpenAI首次陷入此类争议。今年1月,Epoch因在OpenAI宣布o3之后才披露其从OpenAI获得的资金支持而受到批评。许多为FrontierMath做出贡献的学者直到公开时才知道OpenAI的参与。近期还有其他人工智能公司如xAI和meta也因基准测试问题而受到质疑。

这一系列事件不仅揭示了人工智能基准测试中的复杂性和不确定性,也促使人们更加关注模型的透明度和测试实践的合理性。对于消费者和行业观察者而言,保持审慎和理性的态度至关重要。





